• Purpose of the Schema
Ekyam’s Retail Knowledge Graph is a structured representation or graph database that models retail domain entities like (Products, SKUs, categories, vendors, locations, customers, orders etc) and their relationships. The Knowledge Graph is built on Neo4j and encodes the Semantic Schema (Ontology) of the retail domain (for instance, “Product A is supplied by Vendor X” or “SKU123 is stocked at Warehouse Y.”) This structured representation provides a “System of Truth” for facts about products, vendors and static reference data. The Knowledge Graph provides an understanding, contextual linkage and graph-based querying over retail data sourced from MongoDB using Ekyam Standards. Natural Language Queries about product details or vendor relationships are grounded in Ekyam’s Retail Knowledge Graph, which can be queried via graph query APIs or natural-language-to-graph translations.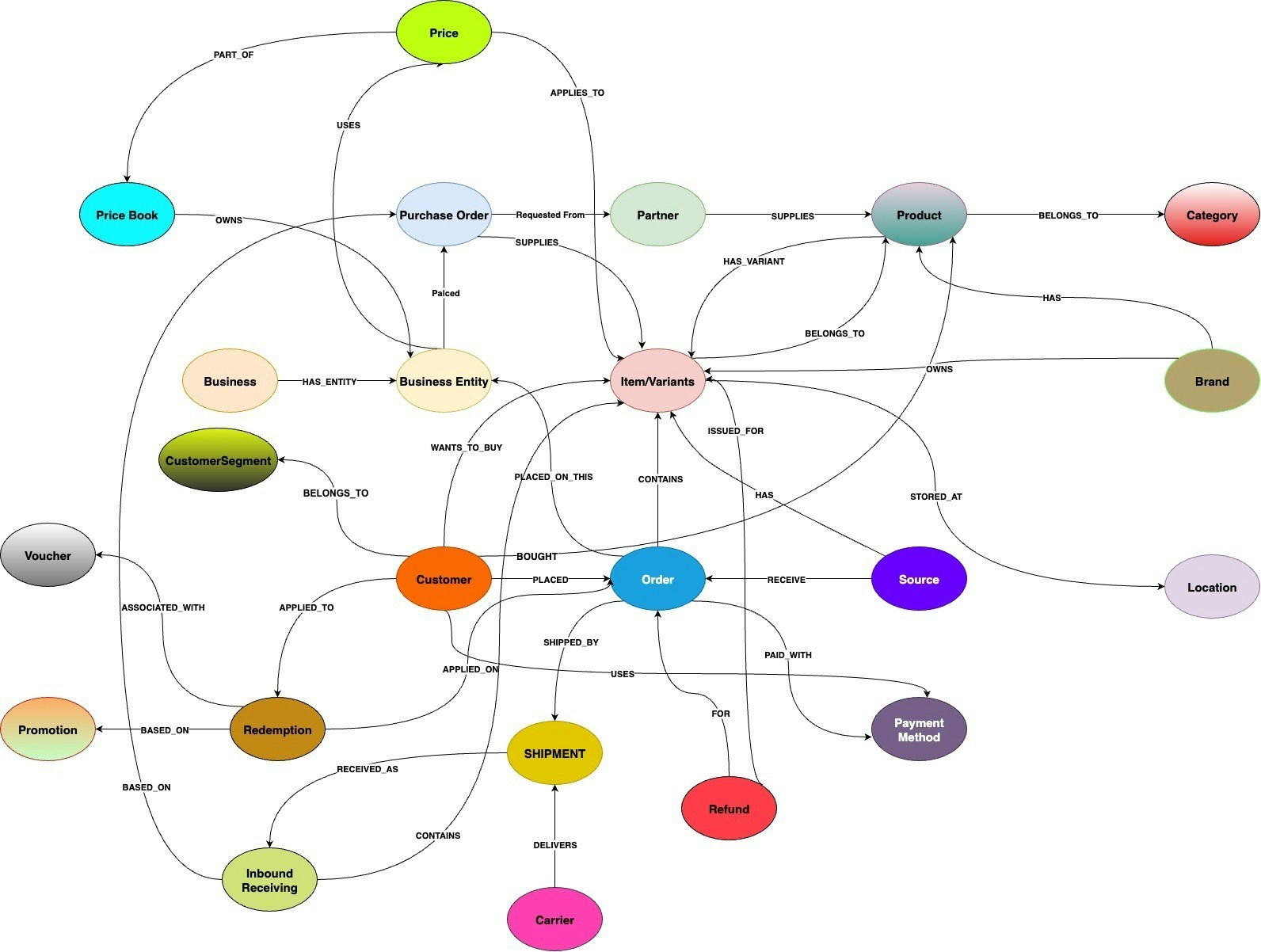
• Why a Graph-based Approach?
A Graph Database is a great way of representing and querying relationships between connected data. Graph databases are chosen to model complex, interconnected relationships (e.g., a customer → order → item → product) that are cumbersome in relational models. A graph-based approach uses a graph structure with attributes, relationships and objects to represent data. Nodes are objects, edges demonstrate the relationship between those nodes, and properties describe the attributes of the nodes and edges. This dynamic structure makes a graph database useful for connected data representation. It offers more flexibility regarding relationships and data types. At its core, a graph database uses a graph structure to represent information:- Nodes act as the individual “objects” or entities (e.g., a customer, an order, a product).
- Edges show the connections or “relationships” between these nodes (e.g., a customer “placed” an order, an order “contains” an item).
- Properties provide details or “attributes” for both nodes and edges (e.g., a customer’s name, an order’s date, an item’s quantity).
While MongoDB stores raw structured data, Neo4j captures semantic relationships, enabling rich queries and reasoning that go beyond flat tables.
• Indispensable Schema Benefits
RKG is a structured knowledge graph that has a capability to interconnect data from disparate sources like inventory, e-commerce websites, product insights etc. This data is organized and structured in a single data management system.Its modular, ontology-driven design, ensures that new node types and relationships can be integrated without disrupting the existing graph structure. The schema is designed to evolve seamlessly with the expansion of retail-entities, easily incorporating new elements like returns, loyalty programs or marketing channels. In addition, if the schema is well-defined, it will ensure data consistency, support interoperability across systems, enable querying and reasoning, thereby providing a clear conceptual model for the graph. It acts as a contract between data ingestion and application layers to minimize ambiguity. Who will benefit from this Schema The schema is intended for developers (for implementation and integration), data scientists (for advanced analytics and ML tasks), and business analysts (for querying business metrics and relationships).• Core Principles
Our Ekyam Retail Knowledge Graph is meticulously designed around several core principles that ensure its robustness, adaptability, and utility across a wide range of applications and future needs. These principles guide every decision in its architecture and implementation:- Flexibility and Extensibility: Ekyam’s Knowledge Graph is capable of accommodating new data sources, and allows seamless incorporation of new domains, entities and relationships.
- Scalability: Ekyam’s Retail Knowledge Graph architecture handles vertical scalability (Increasing resources on a single machine) and horizontal scalability (Distributing data and processing across multiple machines).
- Data Integrity: An important principle is to ensure the accuracy, consistency and reliability of the data within the Knowledge Graph. This involves implementing validation rules, enforcing constraints (uniqueness, data types) and employing mechanisms for data reconciliation and error handling.
- Ease of Querying: Ekyam’s Knowledge Graph is designed to be easily accessible for querying by users, data scientists and developers to business analysts. This includes providing intuitive query languages (e.g., GraphQL, SPARQL, or even natural language interfaces), clear documentation, and tools that simplify data exploration.
• Core Entity Definitions
Node and Relationship Types
A Node in Ekyam’ Retail Knowledge Graph, represents a distinct entity or object in the retail ecosystem such as a Product, Customer or Order. Each node contains key attributes that describe the entity. A relationship type in Ekyam Retail Knowledge Graph defines a connection or interaction between two nodes. For instance, when a customer places an Order, or a Product HAS_VARIANT Item. Relationships are directional and may also include properties (eg. Timestamps, quantities). NodesUse PascalCase (Product, Customer, Shipment) Relationships
Use UPPER_SNAKE_CASE (PLACED, HAS_VARIANT, SOLD_ON)
Relationship names describe actions or associations, while node names reflect entity types.
- Product: It is a generic item for sale that represents a style or a SKU family.
Product - Item Relationships
Ekyam defines a clear relationship between a generic Product and its specific Items. This allows the platform to model a product line where a single product concept can have multiple variations.
- (:Product) [:HAS_VARIANT]-> (:Item) → A product can HAS_VARIANT of one or more items. This means that a broader category (Men’s Tshirts) can have specific items associated with it.
- (:Item) [:IS_VARIANT_OF]> (:Product): An Item IS_VARIANT_OF of a single product.
Inventory Snapshot
This section captures the inventory level of a product or variant at a specific timestamp. The Key attributes include:SKU(Unique), Variant_id, Product_id, Name_at_sale, Price_per_unit, Quantity, Line_item_total, Color, Physical Attributes(Weight, Weight_unit, Length, Width, Height, Dimension_unit)
Product-Item Relationships
This outlines how different entities in a retail context are connected, representing a robust way to model complex relationships, often used in graph databases for efficient querying and insights. → Product and Item (Variant Relationships): (:Product) [:HAS_VARIANT]> (:Item): This models the concept of product variants. (:Item) [:IS_VARIANT_OF]> (:Product): It allows for easy navigation from a specific Item back to its general Product category. → Order and Item Relationships: (:Order)[:HAS_ITEM quantity, price, line_item_total]> (:Item): This represents the line items of an order. (:Item) [:BELONGS_TO quantity, price, line_item_total]>(:Order): Allows for easy querying to find all orders that contain a particular Item. →Item and Source Relationships: (:Item) [:SOLD_ON]> (:Source): Tracks the sales channel or platform where a specific Item was transacted. (:Source) [:HAS]> (:Item): Enables querying to find all Items sold through a specific Source. → Shipment and Item Relationships: (:Shipment) [:CONTAINS_ITEM quantity]> (:Item): Depicts the actual physical movement of goods. A single Order might result in multiple Shipments (e.g., if items are from different warehouses), so tracking Item quantity within a Shipment is critical.(:Item) [:INCLUDED_IN quantity]> (:Shipment): Allows for tracing which Shipments a particular Item was part of.
PurchaseOrder (PO)
The ‘purchase_orders’ collection represents the purchase orders placed by a Business Entity with a Partner. The key attributes include: Po_id, business_entity_id, partner_id, location_id, type, status, order_date, expected_delivery, total_amount, items, is_active, created_at, updated_at, po_number, business_entity_name, partner_name, tax_amount, shipping_amount, grand_total, payment_terms, shipping_method, notes, created_by, approved_by, approved_date.PurchaseOrder Relationships
These relationships illustrate how a PurchaseOrder connects with other critical entities in your business ecosystem, providing a clear map of your procurement process. → (:PurchaseOrder) [REQUESTED_FROM] ->(:Partner): A PurchaseOrder node is linked to a Partner node (representing a vendor or supplier) via the REQUESTED_FROM relationship. This clearly identifies which supplier the goods or services on the purchase order are being requested from. → (:PurchaseOrder) [SUPPLIES] -> (:Item): A PurchaseOrder node is linked to one or more Item nodes via the SUPPLIES relationship. This specifies which particular items (products, goods, services) are included and expected to be supplied by this purchase order. This relationship is fundamental for tracking incoming inventory and matching orders to receive goods.• Ontology Reference
Ekyam’s Ontology Reference establishes a foundational structure and relationships for all retail data ensuring seamless integration across every system. It is the blueprint that makes the data intelligent and interoperable. There are a few Standardized identifiers that allow disparate systems to understand and communicate about the same entities.- Stock Keeping Units(SKUs)
- How are SKUs represented and linked?
- Locations
- Other Key Ontologies
- UOMs are embedded within physical_attributes in the Product node.
- Currencies are defined in the Order node via the currency field.
- Dates/Times are consistently ISO-8601 formatted and used across all temporal fields like created_at, order_created_date, and payment_date.
• Cross-Referencing and Data Linkage
The true power of Ekyam’s ontology lies in cross-referencing and data linkage. This is how Ekyam can transform isolated pieces of information into a cohesive, intelligent graph. How different entities are connected through common identifiers and relationships to form a cohesive graph? Entities are connected using shared identifiers (e.g., product_id, variant_id, order_id, customer_id) through well-defined relationships. This creates a cohesive graph where each node is contextually linked e.g., items sold in orders, shipped in shipments, or placed by customers ensuring complete traceability and semantic richness.• Field-Level Details
Ekyam’s Retail Knowledge graph uses common data types:- String: IDs, names, status, emails, etc.
- Float: Prices, totals, weights, dimensions, etc.
- Integer: Quantities.
- Boolean: Flags like default in addresses.
- Date/Time: All timestamps are in ISO 8601 format (YYYY-MM-DDTHH:MM:SSZ).
- Enum: For fields like status (active, CANCELLED, etc.).
- status = “active” if not provided (by convention).
- created_at = current timestamp (if system-injected).
• Data Integrity Rules
The Ekyam platform incorporates robust Constraints and Validations to ensure the highest level of accuracy. Our validation framework enforces: → All unique ID fields (*_id, order_number, etc.) → Relationships require valid cross-referenced IDs (e.g., variant_id in both Item and Order). → Enumerated fields are validated against allowed sets (like status, method). → Numeric fields (e.g., quantity, price) must be non-negative.• Querying the EKG (via API or UI)
The Ekyam Retail Knowledge Graph is queried via API endpoints using natural language. User queries are passed to a Gemini model along with the graph ontologies, and the model generates Cypher queries to be executed on Neo4j. API endpoints Authentication and Authorization API access is currently open or controlled via environment-level variables, with potential for token-based or basic authentication in production. Query Language/Syntax The system uses natural language queries, which are translated into Cypher by the LLM. Example: User: “Show all orders placed by customer John.” Cypher Generated: MATCH (c:Customer first_name= ‘John’)[:PLACED]>(o:Order) RETURN o• Common Query patterns
Ekyam’s graph-based data model empowers the user to query the retail information with greater flexibility. The user can perform queries that traverse complex relationships. Here are some common, yet powerful, query patterns you can utilize:-
Retrieving a Specific Node by ID: It quickly accesses a particular entity when you know its unique identifier, thereby providing instant access to granular data for deeper analysis.
-
Traversing Relationships: It helps in exploring connections between different entities. This enables understanding the flow of goods and facilitates complex relationship-based analysis.
-
Filtering and Aggregation: This refines the data sets and summarizes information based on the specific criteria and calculations, thereby helping in performance analysis, decision-making capability and summarizing large amounts of data into an explanatory insight.
• Is there a RKG User Interface?
Currently, there is no dedicated UI; the system is API-driven. However, data can be visually explored using Neo4j’s built-in Browser or Bloom tools. While no UI exists, search and filter capabilities are achieved through natural language prompts and LLM-generated Cypher that handles filtering conditions.• Best Practices for Querying
The user can follow below mentioned best practices for querying:- Use clear and concise prompts to guide LLM in generating precise Cypher.
- Include unique IDs or names when referring to specific entities to avoid ambiguity.
- Limit result sets with LIMIT for performance and clarity.
- Avoid over-fetching deeply nested relationships unless required.